HDFS란?
HDFS(Hadoop Distributed File System)는 하둡에서 사용하는 파일 시스템을 말한다. HDFS의 가장 큰 목표는 범용 하드웨어(고가, 저가를 가리지 않는) 분산 파일 시스템을 목표로 한다.
다른 분산 파일 시스템(NFS, CIFS 등)과의 차이는 장애 복구성에 있으며, 별도의 전용 하드웨어는 필요로 하지 않는다.
HDFS는 수백, 수천대의 서버(대규모 클러스터링의 경우)로 구성되기 때문에 결함 탐지 및 신속한 자동 복구 기능이 HDFS 아키텍처의 핵심 목표이다.
HDFS는 사용자와 대화식으로 처리하기 보다는
배치 처리를 위해 설계 되어 있다. 데이터 액세스 속도보다는 데이터 처리량을 높이는 것을 목적으로 한다.HDFS는 WROM(write-once-read-many) 모델로 설계 되었다. 파일이 한번 만들어지면
수정없이, 여러번 읽히는 것을 목적으로 한다.HDFS는 처리 알고리즘이 있는 곳에 데이터를 이동하지 않고, 데이터가 있는 곳에서 처리를 진행한다. 데이터를 이동하는 비용보다 데이터가 있는 곳에서 처리하는 비용이 싸기 때문이다.
HDFS는 빠른 데이터 응답 시간이 필요한 작업, 수많은 작은 파일로 처리 되는 작업, 다중 라이터와 파일의 임의의 작업이 필요한 업무에는 적절하지 않다.
특징 요약
HDFS는 아래와 같은 특징을 가진다.
- 청크 단위 파일 보관
- 큰 파일을 청크 단위로 나눠서 보관하여 크기가 큰 파일도 보관
- 블록 사이즈보다 작은 파일은 파일 그대로 보관
- 분산처리 파일 시스템
- 청크를 다중 노드에 분산하여 보관하므로 장애 복구에 유리(보통 데이터노드 3개씩 분산 저장)
- 범용 장비 사용
- 특성 벤더에 한정되지 않은 장비 사용
- 장애 복구를 위한 레플리케이션
- 복제된 청크를 이용하여 특정 노드의 장애에 무정지 대응 가능 및 장애 대응 가능
- 다만!, 네임노드에 장애가 발생 시 수동으로 복구하여야 함
연산처리
HDFS는
MapReduce 프레임워크를 이용해 데이터 이동없이 분산 저장된 파일을 읽어 연산할 수 있도록 했다.
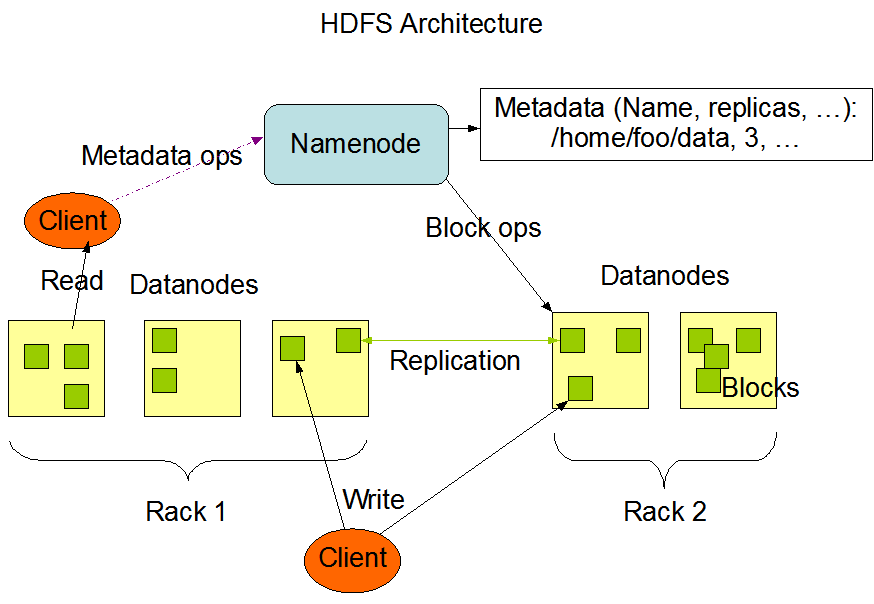
HDFS 노드는 네임노드, 데이터 노드로 나눌 수 있다. HDFS의 네임노드는 모든 파일의 네임 스페이스와 메타 데이터, 파일의 청크 정보를 관리한다.
이 청크는 데이터 노드에 복제 및 저장되고, 이 데이터 노드에서 우리는 연산 처리를 할 수 있다.
- 주의점 : 하둡의
취약점은 많은 개수의 파일을 처리하기에는 적합하지 않다는 것이다. 많은 개수의 파일을 처리한다는 것은 다수의 메타를 알아야 한다는 것이고 이는 곳 네임 노드에 부하를 줄 수 있기 때문이다.
그 외의 분산 파일 시스템
Naver D2를 참고하여 NHN의 기준으로 설명한다.(2013년 기준)
NHN은 NFS, CIFS, OwFS, HDFS 등의 분산 스토리지를 사용한다. 해당 스토리지 등은 각 파일의 크기, 파일의 개수 등에 따라 선택하여 사용하는 것이 현명할 것이다. 하지만 우리가 블로그에서 다루고 있는 빅데이터는 분석을 목표로 하기 때문에 분석기능이 없는 NFS나 CIFS는 선택에서 멀리 치워두는 것이 좋을 것 같다.
각각의 설명은 아래의 참조인 Naver D2 블로그에서 확인해 보자!
| OwFS | HDFS | NFS/CIFS | |
|---|---|---|---|
| 파일 크기 | * 수십 MB 이내의 작은 파일이 많을 때 유리 * 수십 GB 이내의 중간 정도 크기의 파일이 많을 때 유리 | 10GB 이상 큰 크기의 파일이 많을 때 유리 | 작거나 중간 정도 크기의 파일이 있을 때 유리 |
| 파일 개수 | 많을 때 | 적을 때 | 많을 때 |
| TCO(Total Cost of Ownership) | 낮음 | 낮음 | 높음 |
| 분석 기능 | O | O | X |
| 선택 기준 | * 파일이 크지 않을 경우 * 파일이 많은 경우 * 분석이 필요한 경우 | * 파일이 큰 경우 * 파일이 많지 않은 경우 * 용량이 큰 경우 * 분석이 필요한 경우 | * 용량이 작은 경우 * 기존에 NAS를 사용하고 있고, 호환성이 꼭 필요한 경우 |